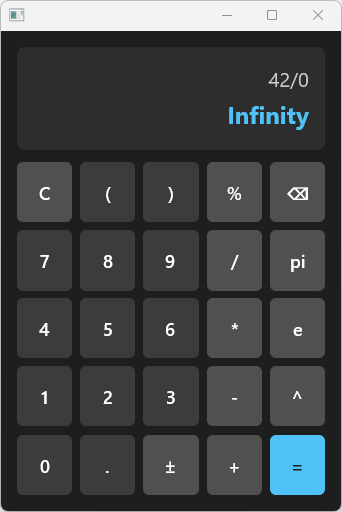
最近用 GPUI 框架實作了一個圖形化計算機,過程中學到不少 Rust 的實用技巧。這篇文章整理了從這個專案中可以學到的 Rust 程式設計概念。
專案概述
這個計算機支援基本四則運算、指數運算 (^)、取餘數 (%)、變數賦值,以及內建常數 pi 和 e。UI 使用 Zed 編輯器團隊開發的 GPUI 框架,這是一個 GPU 加速的 Rust UI 框架。
1. 使用 Enum 定義 Token
Rust 的 enum 非常適合用來定義詞法分析器 (lexer) 的 token 類型:
#[derive(Debug, Clone, PartialEq)]
pub enum Token {
Name(String), // 變數名稱
Number(f64 ), // 數字
Plus, // +
Minus, // -
Mul, // *
Div, // /
Mod, // %
Pow, // ^
Print, // ;
Assign, // =
LP , // (
RP , // )
} 這種設計的好處:
類型安全 :編譯器確保你處理所有可能的 token 類型資料攜帶 :Name(String) 和 Number(f64) 可以攜帶額外資料模式匹配 :配合 match 表達式,程式碼清晰易讀
2. 實作 Iterator Trait
將 lexer 實作為 Iterator,讓程式碼更符合 Rust 慣例:
pub struct TokenStream {
input: Vec< char > ,
offset: usize ,
}
impl Iterator for TokenStream {
type Item = Token;
fn next (& mut self) -> Option< Self::Item> {
loop {
if self.offset >= self.input.len() {
return None;
}
let ch = self.input[self.offset];
self.offset += 1 ;
match ch {
'+' => return Some(Token::Plus),
'-' => return Some(Token::Minus),
'*' => return Some(Token::Mul),
// ... 其他 token
x if x.is_whitespace() => continue ,
_ => return None,
}
}
}
} 實作 Iterator trait 的好處:
可以使用 .collect() 收集所有 token
可以搭配其他 iterator 方法如 .map()、.filter() 等
延遲求值 (lazy evaluation),不會一次解析完整個輸入
3. 遞迴下降解析器
計算機的核心是一個遞迴下降解析器 (recursive descent parser),這是編譯器課程中的經典技術:
impl Calculator {
// 加減法 (最低優先級)
fn expr (& mut self, token: Option< Token> ) -> Result< f64 , String> {
let mut left = self.term(token)? ;
loop {
match self.current_token {
Some(Token::Plus) => left += self.term(None)? ,
Some(Token::Minus) => left -= self.term(None)? ,
_ => return Ok(left),
}
}
}
// 乘除法、取餘數 (中等優先級)
fn term (& mut self, token: Option< Token> ) -> Result< f64 , String> {
let mut left = self.power(token)? ;
loop {
match self.current_token {
Some(Token::Mul) => left *= self.power(None)? ,
Some(Token::Div) => left /= self.power(None)? ,
Some(Token::Mod) => left %= self.power(None)? ,
_ => return Ok(left),
}
}
}
// 指數運算 (高優先級,右結合)
fn power (& mut self, token: Option< Token> ) -> Result< f64 , String> {
let base = self.prim(token)? ;
if let Some(Token::Pow) = self.current_token {
let exp = self.power(None)? ; // 遞迴實現右結合
Ok(base.powf(exp))
} else {
Ok(base)
}
}
// 基本元素 (最高優先級)
fn prim (& mut self, token: Option< Token> ) -> Result< f64 , String> {
// 處理數字、變數、括號、一元負號
}
} 這個設計的關鍵:
運算子優先級 :透過函數呼叫順序自然實現(expr → term → power → prim)結合性 :左結合用迴圈,右結合用遞迴錯誤處理 :使用 Result<f64, String> 和 ? 運算子傳遞錯誤
4. GPUI 的 Render Trait
GPUI 使用 trait 來定義 UI 元件的渲染邏輯:
impl Render for CalculatorApp {
fn render (& mut self, _window: & mut Window, cx: & mut Context< Self> ) -> impl IntoElement {
div()
.flex()
.flex_col()
.size_full()
.bg(rgb(0x1e1e1e ))
.p_4()
.gap_3()
.child(self.render_display())
.child(self.render_keypad(cx))
}
} GPUI 的特色:
宣告式 UI :類似 SwiftUI 或 Flutter 的風格Tailwind 風格的樣式 :.flex()、.p_4()、.gap_3() 等方法GPU 加速 :比 Electron 少 60-80% 記憶體使用量
5. 事件處理與閉包
按鈕點擊事件使用閉包 (closure) 和 cx.listener() 來處理:
div()
.id(SharedString::from(format! ("btn_ {} " , label)))
.on_click(cx.listener(move | this, _event, _window, cx| {
match label_owned.as_str() {
"C" => this.clear(),
"⌫" => this.backspace(),
"=" => this.evaluate(),
"±" => this.toggle_sign(),
"π" => this.append("pi" ),
other => this.append(other),
}
cx.notify(); // 通知 UI 更新
})) 這裡展示了 Rust 閉包的幾個重點:
move 關鍵字將變數所有權移入閉包閉包可以捕獲外部變數(label_owned)
cx.notify() 觸發 UI 重新渲染
6. 模組化設計
專案採用清晰的模組結構:
src/
├── main.rs # 進入點 + UI 元件
└── calculator/
├── mod.rs # 模組宣告
├── token.rs # Token 定義
├── lexer.rs # 詞法分析器
└── parser.rs # 語法分析器 + 測試這種結構的好處:
關注點分離 :UI 和計算邏輯分開可測試性 :parser 可以獨立測試可重用性 :calculator 模組可以用於其他專案
7. 單元測試
Rust 內建強大的測試框架,測試直接寫在同一個檔案:
#[cfg(test)]
mod tests {
use super ::* ;
#[test]
fn test_exponentiation () {
let mut calc = Calculator::new();
assert_eq! (calc.evaluate("2^3" ).unwrap(), 8.0 );
assert_eq! (calc.evaluate("2^3^2" ).unwrap(), 512.0 ); // 右結合
assert_eq! (calc.evaluate("2 + 3^2" ).unwrap(), 11.0 ); // 優先級
}
#[test]
fn test_modulo () {
let mut calc = Calculator::new();
assert_eq! (calc.evaluate("10 % 3" ).unwrap(), 1.0 );
assert_eq! (calc.evaluate("17 % 5" ).unwrap(), 2.0 );
}
} Rust 測試的特點:
#[cfg(test)] 確保測試碼不會編譯進正式版本#[test] 標記測試函數執行 cargo test 即可運行所有測試
8. 錯誤處理
使用 Result 類型和 ? 運算子進行錯誤處理:
pub fn evaluate (& mut self, input: & str ) -> Result< f64 , String> {
self.tokens = TokenStream::new(input).collect();
if self.tokens.is_empty() {
return Err("empty expression" .to_owned());
}
let first_token = self.next_token();
self.expr(first_token)
}
// 使用 ? 運算子傳遞錯誤
fn expr (& mut self, token: Option< Token> ) -> Result< f64 , String> {
let mut left = self.term(token)? ; // 如果 term 失敗,錯誤會被傳遞
// ...
} 這種模式的好處:
明確標示可能失敗的操作
錯誤類型清楚(這裡用 String,正式專案建議用自定義錯誤類型)
? 運算子讓錯誤處理程式碼簡潔
總結
這個計算機專案雖然簡單,但涵蓋了多個重要的 Rust 概念:
概念
應用場景
Enum + Pattern Matching
Token 定義與解析
Iterator Trait
詞法分析器
Recursive Descent
語法分析器
Trait (Render)
UI 元件定義
Closure
事件處理
Module System
程式碼組織
Unit Testing
驗證解析邏輯
Result + ?
錯誤處理
如果你想深入學習 Rust,動手實作一個計算機是很好的練習。從簡單的四則運算開始,逐步加入變數、函數、甚至自定義語法,你會學到很多編譯器和語言設計的知識。
參考資源
用了 Preonic 、Planck 好幾年後,我最近買了 Geonix rev.2 這把 40% 正交鍵盤 (鍵帽使用 NuPhy Shine-through White for Air60 V2) 方便隨身攜帶用。
這篇文章記錄我目前穩定使用的鍵盤配置,包含四層設計的思路與實際鍵位安排。
為什麼是 40% 正交鍵盤
從標準鍵盤轉到正交排列,最直接的好處是手指移動更直覺。傳統 row-stagger 鍵盤的錯位設計是打字機時代的遺留,對現代打字沒有實質幫助,反而讓左手手指需要斜向移動。正交排列讓每根手指都在垂直的軌道上移動,肌肉記憶更容易建立。
40% 鍵盤(60 鍵)看起來很極端,但透過分層設計,所有按鍵都能在手指不離開 home row 太遠的情況下觸及。少了數字行和功能鍵行,雙手的移動範圍大幅縮小,長時間打字反而更輕鬆。
配置總覽
我的配置採用四層設計(完整配置檔可在此下載:geonix_rev_2.layout.json ):
Layer 0 :基礎層,QWERTY 搭配 Home Row ModsLayer 1 :符號層,透過左手拇指啟動Layer 2 :數字與功能鍵層,透過右手拇指啟動Layer 3 :系統層,RGB 控制與其他功能
Layer 0:基礎層
┌
│
├
│
├
│
├
│
└
─
─
─
-
─
─
─
T
─
E
─
/
─
L
─
─
a
─
s
─
S
─
3
─
─
b
─
c
─
f
─
─
─
─
─
t
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
A
─
─
─
─
─
/
─
─
C
─
─
Q
─
C
─
Z
─
t
─
─
─
t
─
─
l
─
─
─
l
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
S
─
─
─
─
─
/
─
─
A
─
─
W
─
A
─
X
─
l
─
─
─
l
─
─
t
─
─
─
t
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
D
─
─
─
─
─
/
─
─
G
─
─
E
─
G
─
C
─
u
─
─
─
u
─
─
i
─
─
─
i
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
F
─
─
─
─
─
/
─
─
L
─
─
R
─
S
─
V
─
1
─
─
─
f
─
─
─
─
─
t
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
T
─
G
─
B
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
S
─
─
Y
─
H
─
N
─
p
─
─
─
─
─
c
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
J
─
─
─
─
─
/
─
─
L
─
─
U
─
S
─
M
─
2
─
─
─
f
─
─
─
─
─
t
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
K
─
─
─
─
─
/
─
─
─
─
I
─
G
─
,
─
←
─
─
─
u
─
─
─
─
─
i
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
L
─
─
─
─
─
/
─
─
─
─
O
─
A
─
─
↓
─
─
─
l
─
─
─
─
─
t
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
;
─
─
─
─
─
/
─
─
─
─
P
─
C
─
─
↑
─
─
─
t
─
─
─
─
─
l
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
'
─
─
─
B
─
E
─
/
─
─
─
s
─
n
─
S
─
→
─
─
p
─
t
─
f
─
─
─
─
─
t
─
─
┐
│
┤
│
┤
│
┤
│
┘
Home Row Mods
基礎層最核心的設計是 Home Row Mods:把 Ctrl、Alt、Gui(Command/Win)、Shift 四個修飾鍵放在 home row 的位置。按住時是修飾鍵,輕點則輸出原本的字母。
左手:
A = Ctrl(按住)/ a(輕點)S = Alt(按住)/ s(輕點)D = Gui(按住)/ d(輕點)F = Shift(按住)/ f(輕點)
右手採用對稱配置,但有個細節:我使用了 MOD_LSFT | MOD_RSFT 這樣的雙邊修飾鍵設定。這讓同手組合鍵(例如右手按 J + K 來輸出 Shift+Gui)更容易觸發,不會因為 timing 問題誤判成連續輕點。
其他設計選擇
方向鍵保留在基礎層 :許多 40% 配置會把方向鍵放到其他層,但我發現導航時常常需要快速切換,放在右下角的位置讓右手小指和無名指自然就能觸及。
- 和 ' 是 Shift-Tap
Esc 在 Caps Lock 位置 :經典的 Vim 使用者配置。
Layer 1:符號層
透過左手拇指按住 MO(1) 進入:
┌
│
├
│
├
│
├
│
└
─
─
─
S
─
─
─
─
E
─
h
─
─
─
~
─
s
─
i
─
─
─
─
c
─
f
─
─
─
─
─
t
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
!
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
@
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
#
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
$
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
%
─
─
[
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
─
─
]
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
&
─
─
=
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
H
─
─
─
─
─
o
─
─
─
─
─
m
─
─
─
─
─
e
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
P
─
─
─
─
─
g
─
─
─
{
─
─
D
─
─
─
─
─
n
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
P
─
─
─
─
─
g
─
─
─
}
─
─
U
─
─
─
─
─
p
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
S
─
─
─
D
─
─
h
─
E
─
─
e
─
─
i
─
n
─
─
l
─
─
f
─
d
─
─
─
─
t
─
─
┐
│
┤
│
┤
│
┤
│
┘
符號層的設計邏輯:
頂排是 Shifted 數字 :!@#$%^&*() 維持與標準鍵盤相同的位置對應,降低學習成本。括號集中在右手 :(), [], {} 三組括號放在右手區域,寫程式時非常順手。-> 巨集導航鍵 :方向鍵位置變成 Home, PgDn, PgUp, End,用於快速跳轉。
Layer 2:數字與功能鍵層
透過右手拇指按住 MO(2) 進入:
┌
│
├
│
├
│
├
│
└
─
─
─
S
─
─
─
─
E
─
h
─
─
─
`
─
s
─
i
─
─
─
─
c
─
f
─
─
─
─
─
t
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
F
─
F
─
─
─
1
─
1
─
7
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
F
─
F
─
─
─
2
─
2
─
8
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
F
─
F
─
─
─
3
─
3
─
9
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
F
─
F
─
─
─
4
─
4
─
1
─
─
─
─
─
0
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
F
─
F
─
─
─
5
─
5
─
1
─
─
─
─
─
1
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
F
─
F
─
─
─
6
─
6
─
1
─
─
─
─
─
2
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
7
─
↓
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
H
─
M
─
─
─
─
o
─
u
─
─
8
─
↑
─
m
─
t
─
─
─
─
e
─
e
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
V
─
─
─
─
E
─
o
─
─
9
─
[
─
n
─
l
─
─
─
─
d
─
-
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
V
─
─
─
─
─
o
─
─
0
─
]
─
─
l
─
─
─
─
─
+
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
P
─
P
─
P
─
─
D
─
g
─
g
─
l
─
─
e
─
U
─
D
─
a
─
─
l
─
p
─
n
─
y
─
─
─
─
─
─
┐
│
┤
│
┤
│
┤
│
┘
這一層的設計重點:
數字在頂排 :維持標準鍵盤的數字位置,直覺好記。F1-F12 在 home row 和下排 :左手區域,與數字層分開。媒體控制在右下角 :靜音、音量、播放暫停,用右手小指區域操作。額外的方向鍵和導航 :↓, ↑ 在 J, K 位置(Vim 風格),搭配 Home, End, PgUp, PgDn。
Layer 3:系統層
透過左下角的 MO(3) 進入:
┌
│
├
│
├
│
├
│
└
─
─
─
─
─
─
C
─
─
─
─
─
4
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
C
─
─
─
─
─
1
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
C
─
─
─
─
─
2
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
C
─
─
─
─
─
3
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
C
─
─
─
─
─
0
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
R
─
─
─
─
─
G
─
─
─
─
─
B
─
─
─
─
─
─
─
─
─
─
M
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
─
─
─
C
─
─
─
─
─
9
─
─
─
─
─
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
R
─
S
─
─
─
─
G
─
P
─
─
─
─
B
─
D
─
─
─
─
+
─
-
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
R
─
─
─
─
C
─
G
─
─
─
─
5
─
B
─
─
─
─
─
-
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
S
─
─
─
─
─
P
─
─
─
─
─
D
─
─
─
─
─
+
─
─
─
─
─
─
┬
│
┼
│
┼
│
┼
│
┴
─
─
─
─
─
─
C
─
─
─
─
─
8
─
─
─
─
─
─
─
─
─
─
─
─
─
─
┐
│
┤
│
┤
│
┤
│
┘
系統層主要用於 RGB 控制:
RGB M:切換 RGB 模式RGB+ / RGB-:調整亮度SPD+ / SPD-:調整動畫速度C0 - C9:自定義功能(可能是 RGB 預設或其他 custom keycode)
使用心得
這套配置已經用了好幾年,從 Preonic 到 Planck 再到 Geonix rev.2,核心邏輯基本沒有大改,只是隨著不同鍵盤的物理配置做微調。
幾個心得:
Home Row Mods 需要調整 timing :預設的 tapping term 通常太短,容易誤觸發。我調整到比較長的數值後才穩定下來。
分層設計要符合使用情境 :左手拇指給符號層(寫程式時左手常按 modifier),右手拇指給數字層(數字輸入時右手主導),這樣的分配比較符合我的使用習慣。
不要一次改太多 :剛開始調整配置時很容易想要一次到位,但肌肉記憶需要時間建立。每次只改一兩個地方,適應後再繼續調整。
40% 的限制反而是優點 :強迫自己思考每個按鍵的使用頻率,最後得到的配置比全尺寸鍵盤更有效率。
如果你也在考慮嘗試小型鍵盤或正交配置,希望這篇文章能提供一些參考。
Rust 的 FFI(Foreign Function Interface)讓我們可以呼叫 C 函式庫,但正確實作並不容易。手寫綁定容易出錯,維護成本高;bindgen 自動產生綁定但仍需要 unsafe;safe wrapper 提供安全的 API 但設計繁瑣。
本文以綁定 FFmpeg 的 libavformat 為例,完整介紹:
三種 FFI 方式 的優缺點比較手寫綁定的常見陷阱 :結構體大小、欄位順序、對齊、生命週期…Bindgen 的工作原理 :如何用 libclang 解析 C 標頭檔Safe Wrapper 設計原則 :RAII、類型狀態、錯誤處理、thiserrorAI Coding Agent 如何加速開發 :讓最佳實踐不再繁瑣
如果你正在考慮綁定一個 C 函式庫,或是想了解為什麼「先用 unsafe 頂著」是個壞主意,這篇文章應該能幫到你。
三種 FFI 方式
1. 手寫 FFI(Manual)
最傳統的方式:手動撰寫 extern "C" 宣告。
#[link(name = "avformat" )]
extern "C" {
pub fn avformat_open_input (
ps: * mut * mut AVFormatContext,
url: * const c_char,
fmt: * const c_void,
options: * mut * mut c_void,
) -> c_int ;
} 優點:
缺點:
容易出錯:必須精確對應 C 的結構體佈局
維護負擔:函式庫更新時需手動同步
ABI 細節容易遺漏
2. Bindgen 自動生成
使用 bindgen 在編譯時從 C 標頭檔自動產生綁定:
// build.rs
let bindings = bindgen::Builder::default()
.header_contents("wrapper.h" , r #"
#include <libavformat/avformat.h>
"# )
.allowlist_function("avformat_open_input" )
.generate()
.expect("Failed to generate bindings" ); 優點:
準確:直接從 C 標頭檔產生
完整:包含所有型別、函式、常數
可維護:標頭檔更新時自動同步
缺點:
編譯時需要 libclang
產生的程式碼冗長
可能包含不需要的內容
3. 安全封裝(Safe Wrapper)
在 bindgen 綁定之上,建立符合 Rust 慣例的 API:
pub struct FormatContext {
ptr: * mut bindgen::AVFormatContext,
}
impl FormatContext {
pub fn open < P: AsRef< Path>> (path: P ) -> Result< Self> {
// 安全的 Rust API,內部處理所有 unsafe
}
}
impl Drop for FormatContext {
fn drop (& mut self) {
unsafe { bindgen::avformat_close_input(& mut self.ptr); }
}
} 優點:
使用者不需要寫 unsafe
RAII 自動管理資源
編譯器協助防止錯誤
缺點:
需要額外的抽象層
可能有輕微的效能開銷
設計 API 需要深思熟慮
手寫 FFI 的常見陷阱
手寫 FFI 看似簡單,但有許多隱藏的坑。以下是實際可能發生的錯誤:
1. 結構體大小不匹配
// 你的定義(40 bytes)
#[repr(C)]
pub struct AVPacket {
pub pts: i64 ,
pub dts: i64 ,
pub data: * mut u8 ,
pub size: i32 ,
}
// 實際 C 結構體(104 bytes)
// 還有很多你沒定義的欄位
後果: 當 FFmpeg 寫入結構體時,會覆寫超出你定義範圍的記憶體 → 程式崩潰或資料損壞。
2. 欄位順序錯誤
// 錯誤的順序
pub struct AVRational {
pub den: c_int , // 你把分母放前面
pub num: c_int ,
}
// C 標頭檔的定義
struct AVRational {
int num; // 分子在前!
int den;
}; 後果: 你的 num 讀到分母,den 讀到分子 → 計算錯誤、除以零。
3. 對齊問題
#[repr(C)]
pub struct Misaligned {
pub flag: u8 ,
pub value: u64 , // 期望 8-byte 對齊
} 後果: 在某些平台上,C 會在 flag 後加 7 bytes 的 padding。如果 Rust 沒有,value 欄位就會讀到垃圾值。
4. 列舉值不匹配
// 你的猜測
pub enum AVMediaType {
Video = 0 ,
Audio = 1 ,
}
// 實際 FFmpeg(不同版本)
// FFmpeg 4.x: Video = 0, Audio = 1
// FFmpeg 6.x: Unknown = -1, Video = 0, Audio = 1
後果: 檢查 if type == Video 可能失敗,因為數值已經偏移。
5. 指標生命週期
// C 函式內部儲存了這個指標
let path = CString::new("/path/to/file" ).unwrap();
avformat_open_input(& mut ctx, path.as_ptr(), .. .);
drop(path); // CString 被釋放!
// ctx 現在持有一個指向已釋放記憶體的懸空指標
後果: Use-after-free → 崩潰或安全漏洞。
6. 呼叫慣例錯誤
extern "C" fn callback (x: i32 ) -> i32 // 假設是 cdecl
// 但 FFmpeg 在 Windows 上可能期望 stdcall
後果: 堆疊損壞、錯誤的返回值。
7. 版本相依的欄位
// 在 FFmpeg 5.0 上正常運作
pub struct AVCodecParameters {
pub codec_type: AVMediaType ,
pub codec_id: u32 ,
pub bit_rate: i64 ,
}
// FFmpeg 6.0 在 bit_rate 之前新增了一個欄位
後果: bit_rate 現在從錯誤的偏移量讀取 → 得到無意義的值。
這就是為什麼 bindgen 是更安全的選擇 。
Bindgen 如何避免這些陷阱
Bindgen 的核心原理是:在編譯時讀取實際的 C 標頭檔,使用 libclang 解析 AST,然後產生對應的 Rust 程式碼 。
工作流程
flowchart TD
A["C 標頭檔 (avformat.h)"] --> B["libclang 解析"]
B --> C["AST(抽象語法樹)"]
C --> D["bindgen 轉換"]
D --> E["Rust 綁定 (bindings.rs)"]
為什麼能避免手寫的陷阱
陷阱
Bindgen 如何解決
結構體大小 從 AST 讀取精確的 sizeof,產生正確大小的 Rust struct
欄位順序 按照 C 標頭檔中的宣告順序產生欄位
對齊問題 讀取每個欄位的 alignof,自動加入正確的 #[repr(C)] 和 padding
列舉值 直接從標頭檔讀取每個列舉的數值
版本相依 每次編譯時重新產生,自動適應安裝的函式庫版本
實際產生的程式碼
當 bindgen 處理 AVRational 時:
// bindgen 產生的程式碼(自動)
#[repr(C)]
#[derive(Debug, Copy, Clone)]
pub struct AVRational {
pub num: ::std::os::raw::c_int, // 順序正確
pub den: ::std::os::raw::c_int,
} 對於複雜的結構體如 AVFormatContext:
// bindgen 產生數百行,包含所有欄位
#[repr(C)]
pub struct AVFormatContext {
pub av_class: * const AVClass,
pub iformat: * const AVInputFormat,
pub oformat: * const AVOutputFormat,
pub priv_data: * mut ::std::os::raw::c_void,
pub pb: * mut AVIOContext,
pub ctx_flags: ::std::os::raw::c_int,
pub nb_streams: ::std::os::raw::c_uint,
pub streams: * mut * mut AVStream,
// ... 還有幾十個欄位 ...
} Bindgen 的限制
Bindgen 不是萬能的,它無法解決 :
1. 跨版本相容性
編譯時:FFmpeg 6.0 安裝 → bindings.rs 對應 FFmpeg 6.0
執行時:FFmpeg 7.0 安裝 → ABI 不相容 → 未定義行為解決方案: 重新編譯,或使用版本檢查。
2. 指標生命週期
Bindgen 只產生型別定義,不會幫你管理生命週期:
// bindgen 產生的函式簽名
pub fn avformat_open_input (
ps: * mut * mut AVFormatContext,
url: * const ::std::os::raw::c_char, // 誰負責這個指標的生命週期?
// ...
) -> ::std::os::raw::c_int; 解決方案: 在 safe wrapper 層處理。
3. 語意正確性
Bindgen 確保 ABI 正確,但不保證你正確使用 API:
// 這段程式碼 ABI 正確,但語意錯誤
let ctx = avformat_open_input(.. .);
// 忘記呼叫 avformat_find_stream_info()
let streams = (* ctx).nb_streams; // 可能是 0 或垃圾值
解決方案: 閱讀文件,或使用 safe wrapper 強制正確的呼叫順序。
結論:三層防護
理想的 FFI 架構是三層:
block-beta
columns 1
block:layer1
A["Safe Wrapper(語意正確性)← 人類設計"]
end
block:layer2
B["Bindgen 綁定(ABI 正確性)← 工具產生"]
end
block:layer3
C["C 函式庫(實際實作)← 外部依賴"]
end
Bindgen 確保 Rust 和 C 之間的 ABI 匹配Safe Wrapper 確保 API 被正確使用人類 負責設計 wrapper 的 API 和處理邊界情況
手寫 FFI 適合學習底層原理,但在生產環境中,bindgen + safe wrapper 的組合才是正確的選擇。
Safe Wrapper 的設計原則
Safe wrapper 是 FFI 的最後一道防線,設計得好可以讓使用者完全不需要接觸 unsafe。以下是幾個關鍵原則:
1. RAII:資源獲取即初始化
原則: 用 Rust 的所有權系統管理 C 資源的生命週期。
pub struct FormatContext {
ptr: * mut AVFormatContext, // C 資源
}
impl FormatContext {
pub fn open (path: & str ) -> Result< Self> {
let mut ptr = std::ptr::null_mut();
let ret = unsafe { avformat_open_input(& mut ptr, .. .) };
if ret < 0 {
return Err(AvError::from_code(ret));
}
Ok(FormatContext { ptr }) // 獲取資源
}
}
impl Drop for FormatContext {
fn drop (& mut self) {
unsafe { avformat_close_input(& mut self.ptr); } // 自動釋放
}
} 效果: 使用者不可能忘記釋放資源,編譯器保證。
2. 類型狀態模式:編譯時強制正確順序
原則: 用不同的類型表示不同的狀態,讓編譯器阻止錯誤的呼叫順序。
// 未初始化的 context
pub struct UninitializedContext { ptr: * mut AVFormatContext }
// 已讀取 stream info 的 context
pub struct ReadyContext { ptr: * mut AVFormatContext }
impl UninitializedContext {
pub fn find_stream_info (self) -> Result< ReadyContext> {
let ret = unsafe { avformat_find_stream_info(self.ptr, .. .) };
if ret < 0 {
return Err(.. .);
}
Ok(ReadyContext { ptr: self .ptr })
}
}
impl ReadyContext {
// 只有 ReadyContext 才能讀取 packets
pub fn read_packet (& mut self) -> Result< Packet> { .. . }
} 效果: 不可能在 find_stream_info() 之前呼叫 read_packet(),編譯器會報錯。
3. 借用而非擁有:避免不必要的複製
原則: 對於 C 結構體內的資料,返回借用而非複製。
impl Packet {
// 返回借用,避免複製整個 packet 資料
pub fn data (& self) -> Option<& [u8 ]> {
unsafe {
let ptr = (* self.ptr).data;
let size = (* self.ptr).size;
if ptr.is_null() || size <= 0 {
None
} else {
Some(std::slice::from_raw_parts(ptr, size as usize ))
}
}
}
} 效果: 零複製存取,效能與直接使用 C API 相同。
4. 錯誤類型化:用 Rust 的 Result 取代錯誤碼
原則: 把 C 的錯誤碼轉換成有意義的 Rust 錯誤類型。
#[derive(Debug, thiserror::Error)]
pub enum AvError {
#[error( "End of file" )]
Eof,
#[error( "Failed to open input: {0}" )]
OpenInput(String),
#[error( "FFmpeg error ({code}): {message}" )]
Ffmpeg { code: i32 , message: String },
}
impl AvError {
pub fn from_code (code: i32 ) -> Self {
if code == AVERROR_EOF {
return AvError::Eof;
}
let message = get_error_string(code);
AvError::Ffmpeg { code, message }
}
} 效果: 使用者可以用 match 處理特定錯誤,IDE 有自動完成。
為什麼用 thiserror?
thiserror 是定義錯誤類型的最佳選擇,原因如下:
1. 自動實作 std::error::Error
// 手寫需要這些
impl std::fmt::Display for AvError { .. . }
impl std::error::Error for AvError { .. . }
// thiserror 一行搞定
#[derive(thiserror::Error)] 2. 錯誤訊息內嵌在類型定義中
#[derive(Debug, thiserror::Error)]
pub enum AvError {
#[error( "Failed to open '{path}': {reason}" )]
OpenInput { path: String, reason: String },
#[error( "Codec not found: {0}" )]
CodecNotFound(String),
} 程式碼和文件在同一處,不會不同步。
3. 支援錯誤鏈(Error Source)
#[derive(Debug, thiserror::Error)]
pub enum AvError {
#[error( "IO error" )]
Io(#[from] std::io::Error), // 自動實作 From<std::io::Error>
#[error( "Invalid path: {0}" )]
InvalidPath(#[source] std::ffi::NulError), // 保留原始錯誤
} 使用者可以用 .source() 追溯錯誤來源。
4. 與 anyhow 完美搭配
// 函式庫用 thiserror 定義具體錯誤
#[derive(thiserror::Error)]
pub enum AvError { .. . }
// 應用程式用 anyhow 統一處理
fn main () -> anyhow ::Result< ()> {
let ctx = FormatContext::open("video.mp4" )? ; // AvError 自動轉換
Ok(())
} 5. 零執行時開銷
thiserror 是純粹的 proc-macro,所有程式碼在編譯時產生,執行時沒有任何額外成本。
比較:不同錯誤處理方式
方式
優點
缺點
返回 i32 錯誤碼
與 C API 一致
無類型安全、難以理解
手寫 Error trait
完全控制
樣板程式碼多
thiserror簡潔、類型安全
需要依賴(但很輕量)
anyhow::Error最簡單
丟失具體類型,不適合函式庫
結論: 函式庫應該用 thiserror 定義具體錯誤類型,讓使用者可以精確處理每種錯誤情況。
5. 隱藏指標:不暴露原始指標給使用者
原則: 所有原始指標都應該是 struct 的私有欄位。
pub struct FormatContext {
ptr: * mut AVFormatContext, // 私有!
}
impl FormatContext {
// 提供安全的存取方法
pub fn nb_streams (& self) -> usize {
unsafe { (* self.ptr).nb_streams as usize }
}
// 如果真的需要原始指標(進階使用),標記為 unsafe
pub unsafe fn as_ptr (& self) -> * mut AVFormatContext {
self.ptr
}
} 效果: 一般使用者完全不需要寫 unsafe。
6. 迭代器模式:讓集合存取符合 Rust 慣例
原則: 用迭代器取代 C 風格的索引存取。
impl FormatContext {
pub fn streams (& self) -> impl Iterator< Item = StreamInfo> + '_ {
(0 .. self.nb_streams()).map(move | i| self.stream_info(i).unwrap())
}
}
// 使用方式
for stream in ctx.streams() {
println! ("Stream {} : {:?} " , stream.index, stream.media_type);
} 效果: 符合 Rust 慣例,可以用 filter、map 等方法鏈。
7. 文件化不變量:清楚說明 Safety 條件
原則: 即使是 safe 函式,也要說明前提條件和可能的 panic。
impl FormatContext {
/// Read the next packet from the container.
///
/// # Returns
/// - `Ok(true)` if a packet was read
/// - `Ok(false)` if end of file reached
/// - `Err(...)` if an error occurred
///
/// # Panics
/// Never panics. All errors are returned as `Err`.
pub fn read_packet (& mut self, packet: & mut Packet) -> Result< bool > {
// ...
}
} 設計檢查清單
設計 safe wrapper 時,問自己這些問題:
問題
如果答案是「否」
使用者需要寫 unsafe 嗎?
提供更高層的 API
使用者可能忘記釋放資源嗎?
實作 Drop
使用者可能呼叫順序錯誤嗎?
使用類型狀態模式
使用者可能傳入無效參數嗎?
在建構時驗證
錯誤訊息有意義嗎?
定義專屬的錯誤類型
API 符合 Rust 慣例嗎?
參考標準庫的設計
好的 safe wrapper 讓使用者感覺像在用純 Rust 函式庫,完全不知道底下是 C。
AI Coding Agent 與 FFI 開發
Bindgen + Safe Wrapper 的組合是最佳實踐,但過去有個問題:太繁瑣了 。
設定 build.rs、處理 pkg-config、設計 wrapper API、實作 Drop、寫文件、寫測試… 這些工作加起來可能比實際的業務邏輯還多。這也是為什麼很多人選擇「先用 unsafe 頂著,以後再說」。
AI coding agent 改變了這個權衡。
AI 擅長的 FFI 任務
1. Build Script 設定
告訴 AI:「用 bindgen 綁定 libavformat,只需要這幾個函式…」
AI 會產生完整的 build.rs:
// AI 產生,包含 pkg-config 偵測、bindgen 設定、錯誤處理
fn main () {
let lib = pkg_config::probe_library("libavformat" )
.expect("libavformat not found" );
let bindings = bindgen::Builder::default()
.header_contents("wrapper.h" , r #"#include <libavformat/avformat.h>"# )
.allowlist_function("avformat_open_input" )
.allowlist_function("avformat_find_stream_info" )
// ... 完整設定
.generate()
.expect("Failed to generate bindings" );
// 輸出到正確位置
bindings.write_to_file(out_path.join("bindings.rs" )).unwrap();
} 手寫這個需要查文件、試錯、處理邊界情況。AI 幾秒鐘搞定。
2. Safe Wrapper 骨架
告訴 AI:「為 AVFormatContext 建立 safe wrapper,實作 RAII」
AI 會產生符合所有設計原則的程式碼:
pub struct FormatContext {
ptr: * mut AVFormatContext,
}
impl FormatContext {
pub fn open < P: AsRef< Path>> (path: P ) -> Result< Self> { .. . }
pub fn nb_streams (& self) -> usize { .. . }
pub fn streams (& self) -> impl Iterator< Item = StreamInfo> + '_ { .. . }
}
impl Drop for FormatContext {
fn drop (& mut self) { .. . }
} 包含:
正確的生命週期標註
Result 錯誤處理迭代器 API
Drop 實作
3. 錯誤類型定義
告訴 AI:「用 thiserror 定義錯誤類型,涵蓋 FFmpeg 的錯誤碼」
#[derive(Debug, thiserror::Error)]
pub enum AvError {
#[error( "End of file" )]
Eof,
#[error( "Failed to open input: {0}" )]
OpenInput(String),
#[error( "FFmpeg error ({code}): {message}" )]
Ffmpeg { code: i32 , message: String },
} 4. 文件和測試
AI 自動產生:
/// # Safety 段落參數和返回值說明
基本的單元測試
使用範例
這些在手動開發時往往被省略,但對使用者很重要。
人類的角色
AI 不是萬能的。人類仍然負責:
任務
為什麼需要人類
決定要綁定哪些函式 需要理解業務需求
審查 API 設計 確保符合 Rust 慣例和使用者期望
驗證 ABI 正確性 編譯成功不代表執行時正確
處理邊界情況 AI 可能遺漏特殊情況
效能調校 需要實際測量和分析
實際工作流程
flowchart TD
A["1. 人類:「綁定 libavformat 的 open/read/close」"] --> B["2. AI:產生 Cargo.toml、build.rs、bindgen 設定"]
B --> C["3. 人類:cargo build,確認編譯成功"]
C --> D["4. AI:產生 safe wrapper(FormatContext, Packet...)"]
D --> E["5. 人類:審查 API,要求修改(「加上迭代器」)"]
E --> F["6. AI:修改 + 補充文件和測試"]
F --> G["7. 人類:用真實檔案測試,確認功能正確"]
整個過程可能只需要 30 分鐘,而不是以前的一整天。
為什麼 FFI 特別適合 AI 輔助
模式明確 :bindgen 設定、RAII wrapper、錯誤處理都有標準模式正確性可驗證 :能編譯、能執行、測試通過重複性高 :每個函式的 wrapper 結構類似文件密集 :需要大量的 Safety 說明和使用範例
AI 處理這些機械性工作,人類專注於設計決策和驗證。
結論
FFI 開發的最佳實踐是 bindgen + safe wrapper :
Bindgen 確保 ABI 正確性(結構體大小、欄位順序、對齊)Safe Wrapper 確保語意正確性(資源管理、呼叫順序、錯誤處理)
過去這個組合太繁瑣,很多人選擇捷徑。現在有了 AI coding agent,完整實作的成本大幅降低。
不要再「先用 unsafe 頂著」了。讓 AI 幫你產生正確的 bindgen + safe wrapper,你只需要審查和測試。
這就是 AI 時代的 FFI 開發:人類做設計決策,AI 做繁瑣實作,最終得到安全、符合慣例的 Rust 綁定。
專案原始碼:rust-52-projects/libavformat-ffi
這個專案是我「52 個 Rust 專案」學習計畫的一部分。在完成了 16 個專案後,我發現 WebAssembly 是一個重要的學習缺口,於是決定用 Rust 來打造一個即時 Markdown 編輯器。
專案原始碼:wasm-markdown-editor
為什麼選擇這個專案?
在分析了之前完成的專案後,我發現幾個學習上的空白:
已掌握的領域 :Async/await、網路程式設計(TCP/UDP/HTTP/WebSockets)、解析器、CLI 工具、錯誤處理待加強的領域 :資料庫 ORM、程序宏、FFI、WebAssembly 、進階測試、GUI/圖形
選擇 Markdown 編輯器的原因:
填補關鍵缺口 :之前沒有任何 WASM 專案善用既有技能 :運用之前在計算機、shell、EBML 等專案中學到的解析技巧互動性強 :能立即看到成果,滿足感高實用價值 :這是真正能用的工具,不只是 demo現代技術棧 :WASM 在 Rust 生態系中越來越重要
技術架構
Rust 依賴項
[dependencies ]
wasm-bindgen = "0.2" # JavaScript 互操作層
pulldown-cmark = "0.12" # 經過實戰驗證的 Markdown 解析器
web-sys = "0.3" # Web API 綁定
serde = { version = "1.0" , features = ["derive" ] }
serde-wasm-bindgen = "0.6" # Rust/JS 之間的資料序列化
console_error_panic_hook = "0.1" # 瀏覽器中更好的錯誤訊息 專案結構
wasm-markdown-editor/
├── Cargo.toml # Rust 專案設定
├── index.html # 主進入點
├── src/
│ ├── lib.rs # WASM 進入點
│ ├── parser.rs # Markdown 解析 + 統計邏輯
│ └── utils.rs # Panic hook 和工具函式
├── www/
│ ├── index.js # JavaScript 應用邏輯
│ └── styles.css # 樣式
└── pkg/ # 建置輸出
├── wasm_markdown_editor.js
└── wasm_markdown_editor_bg.wasm核心實作
將函式匯出到 JavaScript
use wasm_bindgen::prelude::* ;
// WASM 模組載入時自動執行
#[wasm_bindgen(start)]
pub fn init () {
utils::set_panic_hook(); // 更好的錯誤訊息
}
// 簡單的字串轉換
#[wasm_bindgen]
pub fn markdown_to_html (markdown: & str ) -> String {
parser::parse_markdown(markdown)
}
// 複雜結構 → JavaScript 物件
#[wasm_bindgen]
pub fn get_statistics (text: & str ) -> JsValue {
let stats = parser::calculate_stats(text);
serde_wasm_bindgen::to_value(& stats).unwrap()
} 關鍵模式:
#[wasm_bindgen] 標記要匯出給 JS 的函式#[wasm_bindgen(start)] 在模組初始化時自動執行簡單型別(str、數字、布林)自動轉換
複雜型別需要 serde-wasm-bindgen 進行序列化
Markdown 解析
use pulldown_cmark::{html, Options, Parser};
pub fn parse_markdown (markdown: & str ) -> String {
let mut options = Options::empty();
options.insert(Options::ENABLE_STRIKETHROUGH );
options.insert(Options::ENABLE_TABLES );
options.insert(Options::ENABLE_FOOTNOTES );
options.insert(Options::ENABLE_TASKLISTS );
let parser = Parser::new_ext(markdown, options);
let mut html_output = String::new();
html::push_html(& mut html_output, parser);
html_output
} 啟用的功能:刪除線、表格、註腳、任務清單、標題屬性。
統計資訊計算
#[derive(Serialize)]
pub struct Statistics {
pub characters: usize ,
pub characters_no_spaces: usize ,
pub words: usize ,
pub lines: usize ,
pub paragraphs: usize ,
pub reading_time_minutes: f64 ,
}
pub fn calculate_stats (text: & str ) -> Statistics {
let words = text.split_whitespace().count();
let paragraphs = text
.split(" \n\n " )
.filter(| s| ! s.trim().is_empty())
.count();
// 平均閱讀速度:每分鐘 200 字
let reading_time_minutes = (words as f64 / 200.0 ).ceil();
// ...
} JavaScript 整合
import init , {
markdown_to_html ,
get_statistics
} from '../pkg/wasm_markdown_editor.js' ;
async function run () {
// 初始化 WASM 模組
await init ();
// 現在可以使用 Rust 函式了
const html = markdown_to_html (markdown );
const stats = get_statistics (text );
}
// 效能優化:防抖動
let debounceTimer = null ;
const DEBOUNCE_DELAY = 300 ;
function handleInput () {
if (debounceTimer ) clearTimeout (debounceTimer );
updateStatistics (); // 立即更新(快速)
debounceTimer = setTimeout (() => {
updatePreview (); // 防抖動(較重)
saveToStorage ();
}, DEBOUNCE_DELAY );
} 關鍵重點:
ES6 模組匯入 WASM
呼叫 Rust 函式前必須先執行非同步的 init()
防抖動避免過度渲染
統計立即更新(便宜),預覽防抖動(昂貴)
WASM 編譯深入解析
編譯流程
1. Rust 原始碼 (lib.rs, parser.rs, utils.rs)
↓
2. rustc --target wasm32-unknown-unknown
↓
3. 原始 .wasm 二進位檔(WebAssembly 位元組碼)
↓
4. wasm-bindgen(產生 JS 膠水程式碼)
↓
5. wasm-opt(Binaryen 優化)
↓
6. 最終輸出:.wasm + .js + .d.ts記憶體模型
WASM 使用線性記憶體 (單一連續區塊),JavaScript 和 Rust 透過這塊共享記憶體交換資料:
sequenceDiagram
participant JS as JavaScript
participant Mem as WASM 線性記憶體
participant Rust as Rust
JS->>Mem: 1. 寫入字串
JS->>Rust: 2. 傳遞指標 + 長度
Rust->>Rust: 3. 處理資料
Rust->>Mem: 4. 寫入結果
Rust->>JS: 5. 回傳結果指標
JS->>Mem: 6. 讀取結果
JS->>Mem: 7. 釋放記憶體
字串傳遞流程 :
JS 字串寫入 WASM 線性記憶體
傳遞指標和長度給 Rust 函式
Rust 處理資料
Rust 將結果寫入記憶體
回傳結果的指標給 JS
JS 從記憶體讀取結果字串
釋放不再需要的記憶體
型別轉換對照表
Rust 型別
WASM 型別
JavaScript 型別
&str, Stringi32 (ptr) + i32 (len)
string
i32, u32i32
number
f64f64
number
booli32 (0 或 1)
boolean
JsValueexternref
any
可序列化 struct
externref
object
建置與效能
建置指令
# 安裝 wasm-pack(只需一次)
cargo install wasm-pack
# 建置 WASM 模組
wasm-pack build --target web
# 執行 Rust 單元測試
cargo test
# 在瀏覽器中執行 WASM 測試
wasm-pack test --headless --firefox 建置輸出
WASM 套件 :222 KB(已優化)JS 膠水程式碼 :13 KB總下載量 :235 KB建置時間 :約 8 秒(增量)、約 13 秒(完整)
Cargo.toml 關鍵設定
[lib ]
crate-type = ["cdylib" , "rlib" ] # WASM 編譯必需
[profile .release ]
opt-level = "s" # 優化檔案大小(而非速度)
lto = true # 連結時優化,產生更小的套件 為什麼這些設定很重要:
cdylib = C 動態函式庫類型,WASM 必需opt-level = "s" 產生的二進位檔比 “3” 小約 30%LTO 消除整個依賴樹中的死碼
遇到的問題與解決方案
問題:404 錯誤
從 www/ 目錄提供服務時,瀏覽器無法存取 ../pkg/(在提供的目錄之外)。
初始嘗試 :從 www/ 目錄提供服務
http://localhost:8080/ → www/index.html
http://localhost:8080/pkg/... → 404 錯誤解決方案 :在專案根目錄建立 index.html
# 從專案根目錄提供服務,而非 www/
cd wasm-markdown-editor
python -m http.server 8080
# 存取 http://localhost:8080 實作的功能
✅ 帶防抖動的即時預覽
✅ 即時統計(字數、字元數、閱讀時間)
✅ LocalStorage 自動儲存
✅ 帶內嵌 CSS 的 HTML 匯出
✅ 範例 Markdown 載入器
✅ 鍵盤快捷鍵(Ctrl+S、Ctrl+K)
✅ 響應式分割視窗佈局
學習成果
WASM 特定技能
✅ 理解 cdylib crate 類型及其作用
✅ 使用 #[wasm_bindgen] 屬性匯出給 JS
✅ 管理 Rust/JavaScript 邊界的記憶體
✅ 型別轉換(簡單型別 vs. 複雜結構)
✅ WASM 模組初始化模式
✅ 在瀏覽器 DevTools 中除錯 WASM
✅ 套件大小優化技術
✅ 建置工具(wasm-pack、wasm-bindgen)
什麼時候該用 WASM?
適合的場景 :
✅ 計算密集型操作(解析、圖像處理)
✅ 想重用現有的 Rust 函式庫
✅ 效能關鍵路徑
✅ 套件大小可接受時
不太適合的場景 :
❌ 大量 DOM 操作(用 JS)
❌ 微小的工具函式(開銷不值得)
❌ 簡單的 CRUD 操作
❌ 套件大小是關鍵考量時
與純 JavaScript 方案的比較
效能 :
Markdown 解析:比 JS 替代方案快約 2-3 倍
打字時沒有 GC 暫停
可預測的記憶體使用
套件大小 :
與流行的 JS 函式庫相當或更小
markdown-it.js:約 320 KB
我們的方案:235 KB (包含解析器 + 統計)
反思
順利的部分
流暢的建置過程 :wasm-pack「直接就能用」優秀的文件 :Rust WASM book 非常有價值型別安全 :編譯時就能捕捉錯誤效能 :解析明顯流暢工具鏈 :自動產生的 TypeScript 定義很有幫助
克服的挑戰
路徑解析 :404 錯誤需要理解 WASM 服務方式記憶體模型 :理解線性記憶體花了一些時間型別轉換 :學習何時用 JsValue vs. 簡單型別非同步初始化 :理解 init() 的必要性
驚喜的發現
套件大小 :比預期小(222 KB 含完整解析器!)建置速度 :增量建置很快(8 秒)瀏覽器支援 :所有現代瀏覽器都能用,不需要 polyfill開發體驗 :在 DevTools 中除錯 WASM 相當不錯
結論
這個專案成功填補了我 rust-52-projects 學習旅程中的一個主要缺口。它證明了 Rust + WASM 已經可以用於生產環境 的互動式 Web 應用程式,尤其是像解析這樣的計算密集型任務。
Rust 的效能和安全性與 JavaScript 的普及性結合,創造了一個強大的開發模式。工具鏈(wasm-pack、wasm-bindgen)已經成熟到體驗流暢且高效的程度。
這是一個很好的「第一個 WASM 專案」,在學習核心概念的同時建構出真正實用的東西。
參考資源
什麼是 Peacock?
Peacock 是一個非常實用的 VSCode 擴充套件,由 John Papa 開發。它的主要功能是讓你可以為不同的 VSCode 工作區設定不同的顏色主題,透過改變工作區的視窗顏色(包括狀態列、標題列、活動列等),讓你在同時開啟多個專案時能夠快速辨識當前正在工作的專案。
為什麼需要 Peacock?
如果你跟我一樣,經常需要同時處理多個專案,你一定遇過這些困擾:
🔀 在多個 VSCode 視窗間切換時,常常搞不清楚哪個視窗對應哪個專案
💥 不小心在錯誤的專案中編輯或執行程式碼
🎯 想要快速找到特定專案的視窗,但需要逐一檢視
Peacock 透過視覺化的顏色標記,完美解決了這些問題。每個專案都有自己獨特的顏色,一眼就能辨識。
主要功能
工作區顏色化 :自訂狀態列、標題列、活動列等 UI 元素的顏色預設配色庫 :內建多種精心挑選的顏色主題收藏顏色 :可以建立自己的配色收藏清單快速切換 :透過指令面板快速更改工作區顏色專案記憶 :每個工作區的顏色設定會被記錄,重新開啟時自動套用
我的 Peacock 收藏配色
我用 AI 幫我產生一套以品牌和技術堆疊為主題的配色方案。這些顏色不僅視覺上容易辨識,也與對應的技術或品牌有直接關聯,讓我能更直覺地記憶和使用。
品牌主題色系
這些是知名科技品牌的代表色,當我在處理與這些平台相關的專案時特別好用:
顏色名稱
色碼
適用場景
Airbnb Pink
#ff385cAirbnb 相關專案
Amazon Orange
#ff9900AWS 或 Amazon 服務整合
Azure Blue
#007fffAzure 雲端專案
Facebook Blue
#1877f2Meta/Facebook 專案
Google Blue
#4285f4Google Cloud 或 Firebase 專案
LinkedIn Blue
#0a66c2LinkedIn 整合專案
Netflix Red
#e50914串流媒體相關專案
Spotify Green
#1db954音樂或音訊相關專案
Tesla Red
#e82127IoT 或電動車相關專案
Twitter Blue
#1da1f2社群媒體專案
程式語言與框架色系
這是我最常用的部分!根據專案使用的主要技術堆疊選擇對應顏色:
前端技術
React Blue (#61dafb) - React 專案Vue Green (#42b883) - Vue.js 專案Angular Red (#dd0531) - Angular 專案Svelte Orange (#ff3d00) - Svelte 專案Nuxt Green (#00dc82) - Nuxt.js 專案Tailwind Cyan (#06b6d4) - 使用 Tailwind CSS 的專案
後端技術
Node Green (#215732) - Node.js 後端專案Node.js Green (#68a063) - Node.js 全端專案Deno Green (#00a853) - Deno 專案Python Blue (#3776ab) - Python 專案Go Cyan (#00add8) - Go 專案Rust Orange (#ce422b) - Rust 專案PHP Purple (#777bb4) - PHP 專案Ruby Red (#cc342d) - Ruby 專案Java Orange (#007396) - Java 專案Kotlin Purple (#7f52ff) - Kotlin 專案Elixir Purple (#6f42be) - Elixir 專案Scala Red (#dc322f) - Scala 專案C# Purple (#239120) - C# 專案C++ Blue (#00599c) - C++ 專案
框架與工具
Django Green (#092e20) - Django 專案Laravel Red (#ff2d20) - Laravel 專案NestJS Red (#ea2845) - NestJS 專案Spring Green (#6db33f) - Spring Framework 專案Fastify Blue (#000000) - Fastify 專案
JavaScript 生態系
JavaScript Yellow (#f9e64f) - 純 JavaScript 專案TypeScript Blue (#3178c6) - TypeScript 專案Babel Yellow (#f9dc3e) - Babel 設定專案Webpack Blue (#8dd6f9) - Webpack 相關專案ESLint Purple (#4b32c3) - ESLint 設定專案
資料庫與基礎設施
MongoDB Green (#13aa52) - MongoDB 專案PostgreSQL Blue (#336791) - PostgreSQL 專案Redis Red (#dc382d) - Redis 快取專案Docker Blue (#2496ed) - Docker 容器化專案Kubernetes Blue (#326ce5) - K8s 部署專案Firebase Orange (#ffa400) - Firebase 專案GraphQL Pink (#e10098) - GraphQL API 專案
其他科技品牌
GitHub Green (#08872b) - GitHub 相關專案或 Actionsnpm Red (#cb3837) - npm 套件開發Yarn Blue (#2c8ebb) - 使用 Yarn 的專案AMD Red (#ed1c24) - AMD 相關專案Intel Blue (#0071c5) - Intel 相關專案Nvidia Green (#76b900) - GPU 運算或機器學習專案Electron Blue (#47848f) - Electron 桌面應用程式
特殊用途
Jest Red (#c21325) - 測試專案Bootstrap Purple (#7952b3) - Bootstrap 前端專案Mandalorian Blue (#1857a4) - 星際大戰粉絲的選擇 😄Something Different (#832561) - 當你想要與眾不同的時候
如何使用這些配色
1. 安裝 Peacock
在 VSCode 擴充套件市場搜尋 “Peacock” 並安裝,或直接使用指令:
code --install-extension johnpapa.vscode-peacock2. 設定收藏配色
將以下完整配色清單加入你的 VSCode 設定檔(settings.json):
{
"peacock.favoriteColors" : [
{"name" :"Airbnb Pink" ,"value" :"#ff385c" },
{"name" :"Amazon Orange" ,"value" :"#ff9900" },
{"name" :"AMD Red" ,"value" :"#ed1c24" },
{"name" :"Angular Red" ,"value" :"#dd0531" },
{"name" :"Apple Gray" ,"value" :"#555555" },
{"name" :"AWS Orange" ,"value" :"#ff9900" },
{"name" :"Azure Blue" ,"value" :"#007fff" },
{"name" :"Babel Yellow" ,"value" :"#f9dc3e" },
{"name" :"Bootstrap Purple" ,"value" :"#7952b3" },
{"name" :"C++ Blue" ,"value" :"#00599c" },
{"name" :"C# Purple" ,"value" :"#239120" },
{"name" :"Clojure Green" ,"value" :"#5881d8" },
{"name" :"Deno Green" ,"value" :"#00a853" },
{"name" :"Django Green" ,"value" :"#092e20" },
{"name" :"Docker Blue" ,"value" :"#2496ed" },
{"name" :"Electron Blue" ,"value" :"#47848f" },
{"name" :"Elixir Purple" ,"value" :"#6f42be" },
{"name" :"ESLint Purple" ,"value" :"#4b32c3" },
{"name" :"Facebook Blue" ,"value" :"#1877f2" },
{"name" :"Fastify Blue" ,"value" :"#000000" },
{"name" :"Firebase Orange" ,"value" :"#ffa400" },
{"name" :"GitHub Green" ,"value" :"#08872b" },
{"name" :"Go Cyan" ,"value" :"#00add8" },
{"name" :"Google Blue" ,"value" :"#4285f4" },
{"name" :"GraphQL Pink" ,"value" :"#e10098" },
{"name" :"Haskell Purple" ,"value" :"#5e5086" },
{"name" :"Instagram Pink" ,"value" :"#e4405f" },
{"name" :"Intel Blue" ,"value" :"#0071c5" },
{"name" :"Java Orange" ,"value" :"#007396" },
{"name" :"JavaScript Yellow" ,"value" :"#f9e64f" },
{"name" :"Jest Red" ,"value" :"#c21325" },
{"name" :"Kotlin Purple" ,"value" :"#7f52ff" },
{"name" :"Kubernetes Blue" ,"value" :"#326ce5" },
{"name" :"Laravel Red" ,"value" :"#ff2d20" },
{"name" :"LinkedIn Blue" ,"value" :"#0a66c2" },
{"name" :"Lua Blue" ,"value" :"#000080" },
{"name" :"Mandalorian Blue" ,"value" :"#1857a4" },
{"name" :"MATLAB Orange" ,"value" :"#0071c5" },
{"name" :"Meta Blue" ,"value" :"#1877f2" },
{"name" :"Microsoft Blue" ,"value" :"#0078d4" },
{"name" :"MongoDB Green" ,"value" :"#13aa52" },
{"name" :"NestJS Red" ,"value" :"#ea2845" },
{"name" :"Netflix Red" ,"value" :"#e50914" },
{"name" :"Node Green" ,"value" :"#215732" },
{"name" :"Node.js Green" ,"value" :"#68a063" },
{"name" :"npm Red" ,"value" :"#cb3837" },
{"name" :"Nuxt Green" ,"value" :"#00dc82" },
{"name" :"Nvidia Green" ,"value" :"#76b900" },
{"name" :"Perl Blue" ,"value" :"#0073a1" },
{"name" :"PHP Purple" ,"value" :"#777bb4" },
{"name" :"PostgreSQL Blue" ,"value" :"#336791" },
{"name" :"Python Blue" ,"value" :"#3776ab" },
{"name" :"R Blue" ,"value" :"#276dc3" },
{"name" :"React Blue" ,"value" :"#61dafb" },
{"name" :"Redis Red" ,"value" :"#dc382d" },
{"name" :"Ruby Red" ,"value" :"#cc342d" },
{"name" :"Rust Orange" ,"value" :"#ce422b" },
{"name" :"Scala Red" ,"value" :"#dc322f" },
{"name" :"Slack Purple" ,"value" :"#e01e5a" },
{"name" :"Something Different" ,"value" :"#832561" },
{"name" :"Spotify Green" ,"value" :"#1db954" },
{"name" :"Spring Green" ,"value" :"#6db33f" },
{"name" :"Svelte Orange" ,"value" :"#ff3d00" },
{"name" :"Swift Orange" ,"value" :"#fa7343" },
{"name" :"Tailwind Cyan" ,"value" :"#06b6d4" },
{"name" :"Tesla Red" ,"value" :"#e82127" },
{"name" :"Twitter Blue" ,"value" :"#1da1f2" },
{"name" :"TypeScript Blue" ,"value" :"#3178c6" },
{"name" :"Uber Black" ,"value" :"#000000" },
{"name" :"Vue Green" ,"value" :"#42b883" },
{"name" :"Webpack Blue" ,"value" :"#8dd6f9" },
{"name" :"WhatsApp Green" ,"value" :"#25d366" },
{"name" :"Yarn Blue" ,"value" :"#2c8ebb" }
]
} 這份清單包含了 74 種配色,涵蓋主流的程式語言、框架、工具和科技品牌。你可以直接複製整段 JSON 貼到你的設定檔中。
3. 使用配色
開啟專案後,按下 Ctrl+Shift+P(Mac: Cmd+Shift+P)開啟指令面板,輸入 “Peacock”,你會看到以下選項:
Peacock: Change to a Favorite Color - 從收藏清單選擇顏色Peacock: Enter a Color - 輸入自訂顏色Peacock: Surprise Me with a Random Color - 隨機選擇顏色Peacock: Reset Colors - 重設為預設顏色
結語
Peacock 是一個看似簡單,但能大幅提升開發效率的工具。透過視覺化的顏色標記,我再也不會在錯誤的專案視窗中執行不對的指令,也能更快速地在多個專案間切換。
相關連結